Coursera NLP Module 2 Week 4 Notes
Basic Words Vectors
- Numeric Mapping (output vector n = 1) of Vocabulary is simple but add ordering to the words which doesn’t have any semantic sense
- One Hot Vector (output vector n = len(voc)) is simple as well but too sparse (and huge) and also doesn’t allow any comparison since all the words are in orthogonal planes taking all the semantic away (e.g. happy has the same distance to excited than to paper)
- Word Embeddings are the best of both words (output vector n > 1 and n < len(voc) to a reasonable size, like 100). It implicitly has the meaning embedded and allows to calculate semantic distance and possible analogies
How to Create Word Embeddings?
You’ll need: a Corpus of text and an Embedding Method. The Corpus can be general-purpose use as pretrained vectors of wikipedia or specialized with focused topic only. The embedding methods using machine learning explore cbow (Continuous Bag of words) and SkipGram. The Cbow tries to predict a single target word give it’s surrounding words and the Skipgram tries the opposite, predict its neighbors given a target. The task is self-supervised as the text is unlabeled and supervised as the own words give the context and the objective class.
Word Embedding Methods
- Basic Methods
- These use a shallow network with some sampling, preprocessing or lower representation ‘trick’. These are basic because a single words will have the same embedding always.
- word2vec - Shallow Neural Network
- GloVe - Factorizing the corpuses co-ocurrence Matrix
- fastText - Represent words as an n-grams of characters
- Advanced Methods
- These methods take in account the context of the word in a given sequence, therefore the same word can have different embeddings depending on the sentence being applied.
- BERT
- ELMo
- GPT-2
CBOW
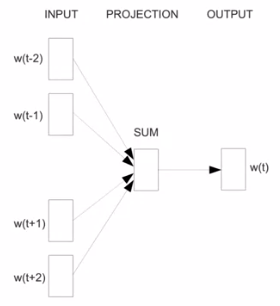
Cleaning and Tokenization


Sliding Window of Words in Python


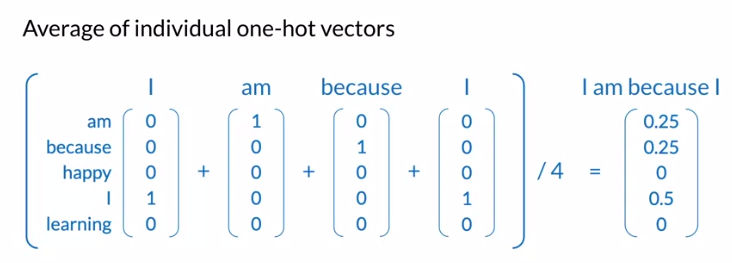
Transforming Words into Vectors

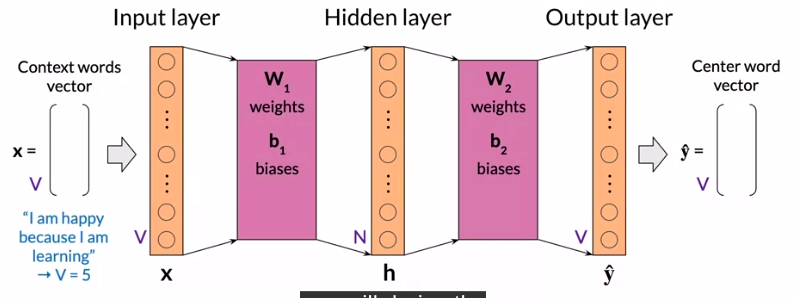
Architecture of the CBOW Model
Evaluation
Intrinsic
- Test relations between words with analogies, clustering and visualization
Extrinsic
- Test word embeddings on external task.